![]()
By Brent Robertson and Michael Bay
It is always exciting watching something launch into space. It is even more thrilling when the launch is the culmination of many years of work. Having worked on a large space-science mission at Goddard Space Flight Center, we had the privilege of working with a team of people dedicated to developing a one-of-a-kind scientific satellite that would do things never done before. Watching the Atlas V blast off from the Cape with our satellite onboard was a moment of truth. Would the satellite perform as designed? Had we tested it sufficiently before launch? Did we leave a latent flaw? Had we used our resources wisely to achieve the greatest possible scientific benefit?
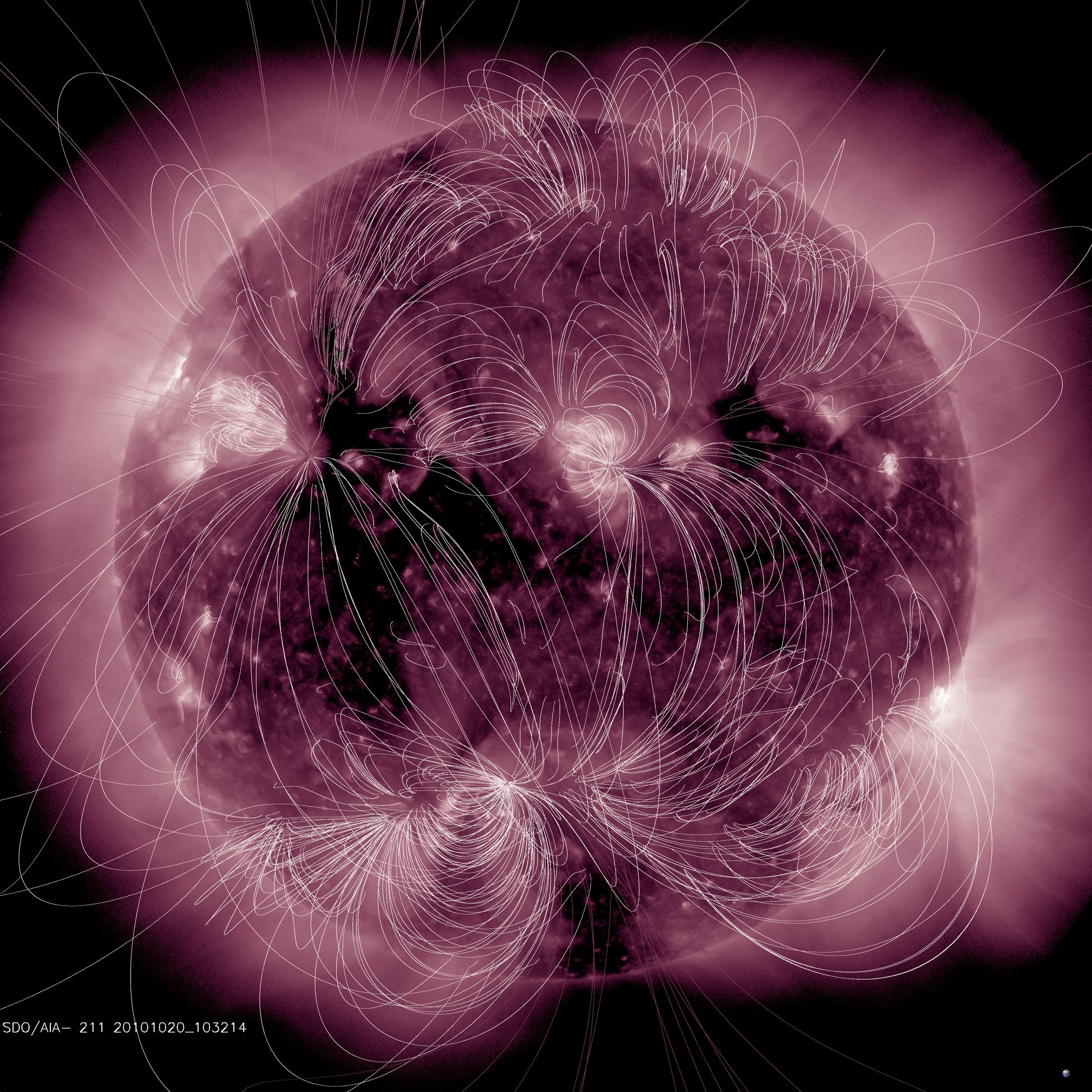
This illustration maps the magnetic field lines emanating from the sun and their interactions superimposed on an extreme ultraviolet image from SDO.
Photo Credit: NASA/SDO
The Solar Dynamics Observatory (SDO) mission is changing our understanding of the dynamic structure of the sun and what drives solar processes and space weather, which affect our lives and society. Goddard led the team who built the spacecraft in house, managed and integrated the instruments, developed the ground system and mission operations, and performed observatory environmental testing. We had a compelling mission, adequate funding, a seasoned project management team, and a strong systems-engineering and quality-assurance staff. The instrument investigations were provided by highly competent and experienced organizations at Stanford University, the Lockheed Martin Solar and Astrophysical Laboratory, and the University of Colorado Laboratory of Atmospheric and Space Physics. It’s what we considered a dream team for mission development.
SDO was a technically challenging mission with stringent science requirements necessitating the application of new technology in a severe orbital environment. In order to mitigate potential threats and ensure success, the SDO project instituted a thorough “test like you fly” philosophy at the system level along with a rigorous risk management and problem-tracking approach. A risk identification and mitigation process was put in place for everyone to use early on. As we moved from the design to the build phase, we emphasized stringent problem investigation, tracking, and closeout across the entire project. This process proved to be an effective technique to aggressively identify and track threats to mission success. We found and resolved system-level anomalies that otherwise might have gone unreported or been left open. The result was reflected in the findings of the SDO prelaunch safety and mission success review, where it was noted that there were fewer residual risks than normal.
Like most projects, SDO encountered a number of programmatic and technical issues throughout its development. Looking back at these issues affirms a number of lessons that may be useful for other projects. A budget rescission just after critical design review removed 30 percent of the funding at a critical time during development. The project was forced to slow down instrument development and defer spacecraft procurements. At the time, we gave up some schedule reserve. The launch readiness date slipped by only four months, but we realized in hindsight it was not a wise decision. We later encountered delays in flight-hardware deliveries due to challenges in developing high-speed bus electronics needed for transferring large quantities of data for transmission to Earth. The launch readiness date slipped another four months, which meant SDO lost its launch slot. Due to a backlog of Atlas V launches, a four-month slip ended up costing the project another fourteen months waiting for its turn to launch. We were very worried that we would lose critical people to other jobs during the wait, but in the end almost all the original team supported launch. Lesson affirmed: Giving up schedule reserve before starting a flight-build effort is a mistake.

A rather large M 3.6–class flare occurred near the edge of the sun on Feb. 24, 2011; it blew out a waving mass of erupting plasma that swirled and twisted for ninety minutes.
Photo Credit: NASA/SDO
Looking back at the technical issues encountered by SDO, we can identify some as “high consequence.” These were issues that required rework of flight hardware, issues whose resolution held up integration and test efforts, or issues that could not be fully mitigated and resulted in a residual risk at launch. Could these issues have been avoided? Maybe some of them. Unexpected events always happen, especially when building a one-of-a-kind spacecraft. That is why we test. More than half these issues were due to interactive complexity among components that was hard to predict analytically and could only be discovered after system integration. What is worth noting is how these issues were identified and how they manifested themselves.
Some issues were discovered with vendor components after they were delivered to the project. Although the vendor was required to subject components to an environmental test program, component testing did not always uncover all problems. For example, one component had a latent workmanship issue that was not discovered until thermal-vacuum testing. The device experienced anomalous behavior in a narrow temperature range. The problem was caused by an incorrect number of windings on an inductor that was selectable by an operator during the unit’s building and testing. The device’s functional performance had been verified by the vendor at the plateaus of component-level thermal testing but not during transitions. Lesson affirmed: Not all test programs are equal; what matters is having the right test program and, in this case, functional testing as temperatures vary over their full range.
Another example involved the identification of a shorted diode on a component’s redundant power input. Component-level testing verified the power-input functions one at a time but did not specifically test for power-feed isolation between redundant inputs. This short was not discovered until the component was powered by a fully redundant system on the observatory during a test designed to show power bus isolation. Such “negative testing,” designed to verify protective functions, had uncovered a problem and was necessary to show the mission could continue in spite of failures. Lesson affirmed: Verifying functions may need negative testing at the system level, especially where protective or isolating features are intended.
Both of these components were de-integrated from the observatory and returned to the vendor for repair, which delayed the completion of system integration and testing. But it was better to find these problems prelaunch instead of on orbit.
Not all test programs are equal; what matters is having the right test program and, in this case, functional testing as temperatures vary over their full range.

Moments after launch, SDO’s Atlas V rocket flew past a sundog and, with a rippling flurry of shock waves, destroyed it.
Photo Credit: NASA/Goddard/Anne Koslosky
The SDO design used common products in multiple sub-systems. This was not only cost efficient but also allowed for the discovery of potential issues through testing a larger number of common units, thereby enabling reliability growth. For instance, a common low-power switch card used in eight locations had a latent flaw that was found during the build of a flight spare unit. A short to ground that had not been uncovered during the testing of other similar cards due to a marginal tolerance was discovered. A possible on-orbit problem potentially induced by launch vibration or extensive thermal cycling was averted by having a design with a common product. Unfortunately, five electronics boxes were affected and all of them were already integrated on the observatory. We decided to de-integrate the boxes and fix the problem. It could have been worse; the observatory had not yet gone through its thermal-vacuum testing. But it was unnerving to find a problem like this so late in the test program. Lesson affirmed: The devil is in the details and the details can’t be ignored, as Murphy’s Law and Mother Nature will show you in flight, sometimes in dramatic fashion.
One issue not due to complexity occurred during a bakeout. Most of SDO’s hardware had been baked to remove contaminants; the satellite’s high-gain antenna subsystem was one of the last pieces of hardware needing a bake-out. It was just another bake-out; what could go wrong? It turned out that the facility control software for test heaters was left turned off and nobody noticed that the uncontrolled test heaters subjected the hardware to damaging hot temperatures until it was too late. The good news was we had spares on hand to rebuild the subsystem, but this was a problem that could have been avoided. Lesson affirmed: Apply product savers1 to protect flight hardware from damaging conditions should test environments run awry, and continuously assess what can go wrong during testing of flight hardware, no matter how often similar tests have been performed.

One of the four Atmospheric Imaging Assembly telescopes arrives at Goddard for integration and testing.
Photo Credit: NASA
SDO used a rigorous “test like you fly” approach at the system level to find issues that might have escaped detection during design, review, and lower-level testing. In today’s systems, where interactive complexity can conceal potentially serious issues and impede our ability to foresee failure, it is essential to understand mission-critical functions and work tirelessly to uncover the “unknown unknowns.” It was especially critical to apply a “test like you fly” philosophy to increase the chance of finding the latent flaws that matter. Often, seemingly small problems and failures are the tip of an iceberg threatening something bigger. Many loss-of-mission failures are foreshadowed by prelaunch discrepancies. It was not good enough just to make things work. We needed to make sure we identified and understood why they didn’t work and then properly obviate or mitigate that cause.
SDO was scheduled for launch on Feb. 11, 2010. But the SDO team was challenged one last time, when a winter “storm of the century” closed much of the Washington, D.C., area, where the Mission Operations Center was located. Undaunted, the entire team made it in to support the launch. It was a spectacular launch, with the rocket flying through a rainbow known as a sun dog, which the rocket’s shock wave extinguished. The rocket did its job, placing SDO in a geosynchronous transfer orbit.
Since then, on-orbit science operations continue to exceed requirements and the spacecraft has performed flawlessly. The few residual risks accepted at the time of launch have not come to pass. The use of a rigorous process to uncover potential problems was a success. The technical issues, the wait for a launch, the snowstorm—all these challenges had been met. The years of hard work from many talented people paid off.
About the Authors
 |
Brent Robertson is currently the deputy project manager for the Magnetospheric Multiscale project at Goddard Space Flight Center. He has held a number of positions at Goddard, including observatory manager for the Solar Dynamics Observatory, associate division chief, branch head, and lead engineer for numerous spacecraft efforts. E-mail: brent.robertson@nasa.gov |
|
 |
Michael Bay currently serves on the Goddard Space Flight Centers Global Precipitation Measurement mission systems engineering team and participates in NASA Engineering and Safety Center assessments for the avionics and systems engineering technical discipline teams. He served on the SDO systems engineering team and has thirty-three years experience developing, testing, and operating space systems. He is chief engineer of Bay Engineering Innovations. E-mail: michael.bay@bayengineering.org |
More Articles by Brent Robertson
- Sharing Responsibility for Risk (ASK 24)
1. A product saver provides an independent shut-off of a potentially threatening environment (vibration, thermal) in case the prime environmental controller fails.